分布式唯一id浅谈
为什么需要分布式唯一ID
在许许多多的场景中,我们都需要一个全局唯一的ID来作为标识,常见的比如订单号,流水号等等。在单机环境下,可以通过automatic自增操作来实现,但是对于分布式场景,如何获得这样一个全局唯一的ID就成了问题。
分布式唯一ID应该有怎样的特征
- 全局唯一性:不能有任何冲突可能
- 递增属性:严格递增/趋势递增
- 获取高效:每一个ID的获取成本应该在us级别
怎么获得分布式唯一ID
在传统的架构中,对于这种唯一的ID,都直接使用数据库,比如mysql的自增ID列作为唯一ID。可是当你的业务量巨大,开始使用分库分表架构的时候,这种方式就显得无能为力了。其次,如果你的业务需要提前获得一个ID,以便上下游业务能顺利处理,那么这种落库生成ID的方式就有些力不从心了。
那么,在这种分布式场景下,怎样才能获得分布式唯一ID呢?
数据库批量生成方式
在上面的讨论中,我们可以看到,通过mysql的自增主键,可以实现单机的唯一ID。那么,如果将这种方案改造一下,继续利用mysql,是否也可以实现呢?答案是肯定的。
我们可以创建下面这样一张表:
| business | id |
|---|---|
| b1 | 1000 |
第一列用来标识不同的业务,然后第二列id则是当前使用了的最大的id号。
那么怎么利用这行数据来产生ID呢?
其实这里可以利用mysql的事务的原子性特点,执行下面一个事务:
set AutoCommit=false;
update tb1 set id += 1000 where business = b1;
select id from tb1 where business = b1;
commit;
这样执行以后,查询出来的id就是获得的最大id号,那么区间(id - 1000, id]的id号就是当前进程获得的全局唯一ID。
这种方式的有点事能够获得全局严格递增的id,但是缺点很明显,就是因为所有的请求都到了mysql这样一个单点的服务上面,所以在性能上会有很大的问题。因为每次获取id的时候,也就需要通过批量获取的方式来平衡性能损失。
分布式规则方式生成方式
因为利用mysql会有单点性能问题,那么我们又能否通过一种统一的算法来让每个进程按照某种既定的规则,自己生成全局唯一的ID呢?
要解决这个问题,我们就得先从分布式唯一ID的几个特征入手:
- 全局唯一性:要解决这个问题,我们会想,如果给每台机器指定一个唯一的数字,然后只生成这个数字,那么每个进程之间生成的ID就一定不会相同。可是这样会让每个进程自己生成的ID重复,所以,如果每个进程先随机生成一系列不相同的数字,然后在前缀、后缀或者中间固定的某个位置放上自己的唯一id,那么这样是不是不仅进程间id不同,连自己每次生成的id也就不同了。
- 递增属性: 在单进程内实现递增是很容易的,最简单的方式就是使用automatic变量来不断++。但是这样在同一时间不同的进程间产生的id就有可能差别很大,甚至有可能某个进程的id一直小于另一个进程很久之前产生的id,比如两个进程当前最大id都是100xx,但是某个进程突然挂掉,然后重启继续从100xx开始生成id,但是另一个进程,此时生成的id已经是10000xx,这会导致此后生成的id就不再满足递增属性了。要解决这个问题,最简单的方式就是找一个天然自增的东西,比如时间戳。这样重启后,依旧可以保持递增趋势
- 高效:如果只是简单地数字运算,那么每秒可以轻轻松松产生百万的id
snowflake
snowflake是Twitter提出的一个高效的分布式唯一ID算法。这个算法就利用时间戳+machineID的方式来实现的。
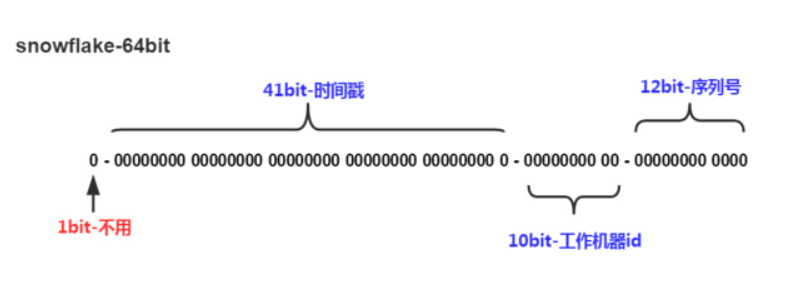 它用41bit的毫秒数,作为时间戳区段,然后machineID字段使用10bit,其中5个bit是数据中心编号,5个bit是机器编号,最后用12个bit来作为单个进程内的自增流水号(0-1023),然后在起始位用一个0来凑足64位long型ID。
这个算法,因为基本就是二进制计算,所以效率极高。但是这个算法并不算完美,还有以下几个问题需要解决:
它用41bit的毫秒数,作为时间戳区段,然后machineID字段使用10bit,其中5个bit是数据中心编号,5个bit是机器编号,最后用12个bit来作为单个进程内的自增流水号(0-1023),然后在起始位用一个0来凑足64位long型ID。
这个算法,因为基本就是二进制计算,所以效率极高。但是这个算法并不算完美,还有以下几个问题需要解决:
- 1毫秒内如果需要生成的id超过1024个怎么办?因为12bit只能表示1024个数字,所以超过1024个就不能唯一生成了,所以此时的解决办法是:sleep直到下一个毫秒,然后从0开始。
- 出现时钟回拨怎么办?因为人为误操作因素、NTP时钟同步、闰秒等原因导致时钟回拨,则会导致id冲突,这时就采取停等,直到时钟大于上一次的时间戳才重新开始分配id。
除了上面两个问题,还有就是在一些根据后缀取模做hash的分库分表场景,如果每毫秒生成的id太少,会造成id集中分布在后缀很小的范围内,这样会导致数据分布不均。此时可以通过每次从一个随机数开始递增或者流水号不用每毫秒置0,而是不断循环自增来解决。
MongoDB ObjectId

如上图所示,mongodb的ObjectId也是采用了类似的思想,不过snowflake是以毫秒作为一个周期,ObjectId是以秒作为周期来进行计数。
不管是snowflake还是mongodb ObjectId这种基于分布式规则的方案都十分高效,但是都有一个问题,就是生成的id只能趋势递增,而不能实现严格递增。所以有没有一种方案,既高效,又能严格递增呢?博主表示可以思考一下。
单机令牌方式
博主最近看了一下spanner的论文,受到里面TrueTime的启发,然后再联想到公司的令牌限流方案,就脑洞大开想到一种将两种技术结合的方案,可以高性能支持严格的单调递增全局唯一id。
整个方案是
